# '%pip install qrcode[pil] -q'
# import qrcode
# import matplotlib.pyplot as plt
# import seaborn as sns
# import numpy as np
# import pandas as pd
# import statsmodels.api as sm
# from matplotlib.backends.backend_pdf import PdfPages
# from google.colab import files
# # --- 1. КОНФИГУРАЦИЯ ---
# pdf_filename = "Election_Analysis_2026_Final_Report.pdf"
# gist_url = "https://gist.githubusercontent.com/gregordimi/e0d3fe30e4f898c84ad25c38b39f6e44/raw/311a84fb7ce48c8bc47d61b359405d602b2aabd6/results2026.json"
# notebook_url = "https://colab.research.google.com/drive/1Zu_q3iuHCEs0OmtctdoCo3ef7LvgTeru?usp=sharing"
# author_url = "https://linkedin.com/in/grigordimitrov"
# election_date = pd.to_datetime('2026-04-19')
# PAGE_SIZE = (11, 8.5)
# def get_qr_image(url):
# qr = qrcode.QRCode(box_size=10, border=2)
# qr.add_data(url)
# qr.make(fit=True)
# return qr.make_image(fill_color="black", back_color="white")
# def add_footer(fig, page_num, total_pages):
# footer_text = f"Източник: Публични данни - Сайтове на агенции / Медии | Стр. {page_num} от {total_pages} | Забележка: Данните са събирани чрез бот, възможни са неточности"
# fig.text(0.5, 0.04, footer_text, ha='center', fontsize=8, color='grey', alpha=0.7)
# # --- 2. ПОДГОТОВКА НА ДАННИ ---
# party_cols = [c for c in df.columns if c in actual.index]
# cols = [c for c in df.columns if c not in ['Agency', 'Date', 'metadata', 'Не съм решил']]
# def calculate_metrics(row):
# diffs = row[party_cols] - actual[party_cols]
# return pd.Series({'MAE': np.abs(diffs).mean(), 'RMSE': np.sqrt((diffs**2).mean())})
# metrics_all_df = df.apply(calculate_metrics, axis=1)
# ols_list = []
# for idx, row in df.iterrows():
# enc = row['metadata'].get('encoded', {})
# if not enc: continue
# ols_list.append({
# 'Label': idx,
# 'MAE': metrics_all_df.loc[idx, 'MAE'],
# 'RMSE': metrics_all_df.loc[idx, 'RMSE'],
# 'Is_Hybrid': 1 if enc.get('methodology') == 'hybrid' else 0,
# 'Days_To_Election': (election_date - pd.to_datetime(enc.get('date'))).days,
# 'Sample_Size': enc.get('sample_size', 0)
# })
# reg_df = pd.DataFrame(ols_list).dropna()
# X_reg = sm.add_constant(reg_df[['Is_Hybrid', 'Days_To_Election', 'Sample_Size']])
# model_mae = sm.OLS(reg_df['MAE'], X_reg).fit()
# model_rmse = sm.OLS(reg_df['RMSE'], X_reg).fit()
# target_parties = ['Прогресивна България', 'ГЕРБ', 'ПП-ДБ', 'ДПС', 'Възраждане']
# sorted_parties = actual[cols].sort_values(ascending=False).index
# total_p = 7 + len(target_parties)
# with PdfPages(pdf_filename) as pdf:
# # --- СТРАНИЦА 1: ЗАГЛАВИЕ (ADJUSTED) ---
# fig = plt.figure(figsize=PAGE_SIZE)
# plt.axis('off')
# # DRAFT воден знак
# plt.text(0.5, 0.96, 'DRAFT V2', ha='center', va='center', fontsize=40, fontweight='bold', color='red', alpha=0.7)
# # Заглавие и Подзаглавие
# plt.text(0.5, 0.88, 'Анализ на социологическата точност: Избори 2026', ha='center', fontsize=24, fontweight='bold', color='#003366')
# plt.text(0.5, 0.80, 'Статистически анализ на факторите, влияещи върху грешката', ha='center', fontsize=14, style='italic', color='#444')
# # Секция АВТОР И ЛИНКОВЕ
# # Използваме url= параметър за кликаемост в PDF
# plt.text(0.1, 0.70, f'Автор: Г. Д.', fontsize=12, fontweight='bold', color='#003366')
# plt.text(0.1, 0.67, 'LinkedIn Профил', fontsize=11, color='blue', url=author_url, bbox=dict(facecolor='none', edgecolor='none', pad=0))
# plt.text(0.1, 0.63, 'Източник на данни', fontsize=11, color='blue', url=gist_url)
# plt.text(0.1, 0.59, 'Код на анализа', fontsize=11, color='blue', url=notebook_url)
# plt.text(0.1, 0.54, f'Дата на анализ: {pd.Timestamp.now().strftime("%d.%m.%Y")}', fontsize=10, color='#666')
# # Блок с метрики
# metrics_note = ("• MAE (Средна абсолютна грешка): Линейно отклонение на прогнозата.\n"
# "• RMSE (Средноквадратична грешка): Подчертава големите индивидуални пропуски.\n"
# "• OLS Regression: Идентифицира кои фактори (метод, време, извадка) са статистически значими.")
# plt.text(0.1, 0.40, metrics_note, fontsize=10, bbox=dict(facecolor='#f0f0f0', alpha=0.5, edgecolor='none', pad=5))
# # QR Кодове (Запазваме ги като визуален елемент)
# ax_qr0 = fig.add_axes([0.20, 0.12, 0.15, 0.15]); ax_qr0.imshow(get_qr_image(author_url), cmap='gray'); ax_qr0.axis('off'); ax_qr0.set_title("Автор", fontsize=8)
# ax_qr1 = fig.add_axes([0.42, 0.12, 0.15, 0.15]); ax_qr1.imshow(get_qr_image(notebook_url), cmap='gray'); ax_qr1.axis('off'); ax_qr1.set_title("Код", fontsize=8)
# ax_qr2 = fig.add_axes([0.64, 0.12, 0.15, 0.15]); ax_qr2.imshow(get_qr_image(gist_url), cmap='gray'); ax_qr2.axis('off'); ax_qr2.set_title("Данни", fontsize=8)
# add_footer(fig, 1, total_p)
# pdf.savefig(fig, dpi=300, bbox_inches='tight'); plt.close()
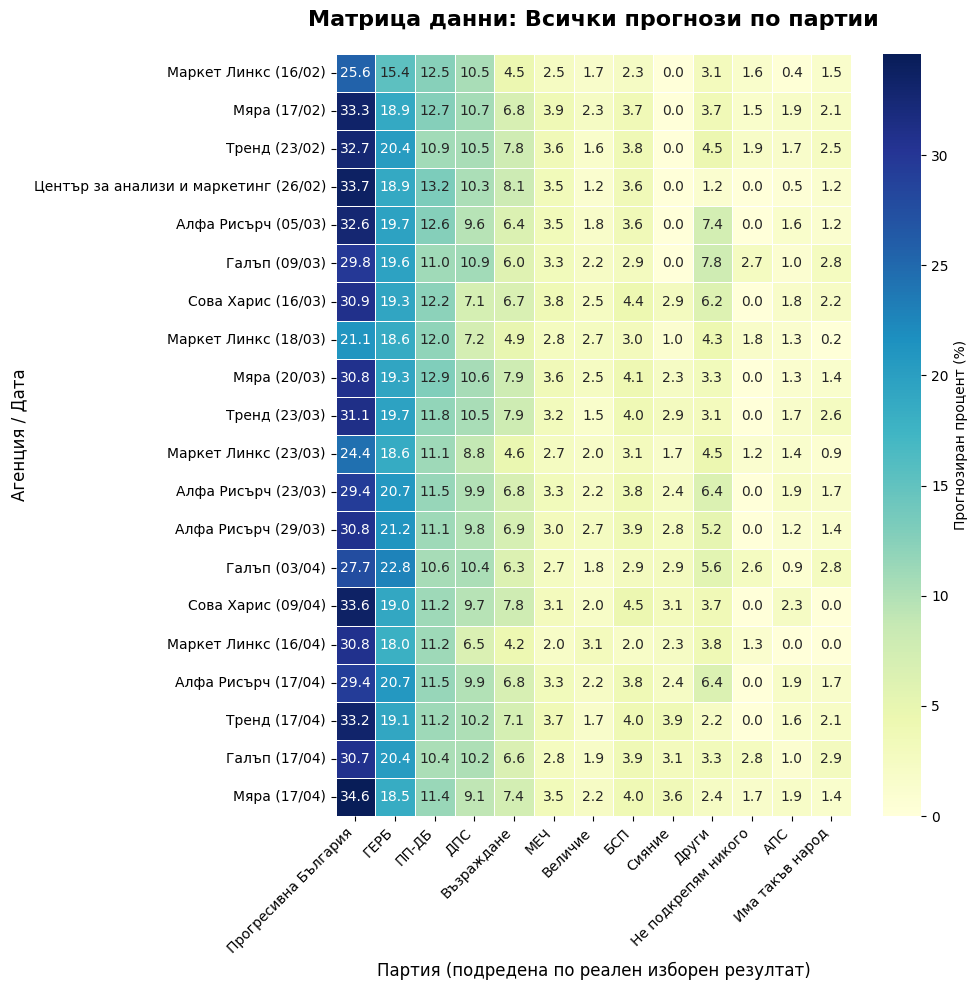
# # --- СТРАНИЦА 6: МАТРИЦА НА ДАННИ ---
# fig = plt.figure(figsize=PAGE_SIZE)
# sns.heatmap(df[sorted_parties], annot=True, fmt='.1f', cmap='YlGnBu', annot_kws={"size": 8}, cbar_kws={'shrink': 0.8})
# plt.title('Матрица на данните: Всички прогнози (%)', fontsize=16, fontweight='bold')
# plt.xticks(rotation=45, ha='right', fontsize=9); plt.yticks(fontsize=8)
# plt.tight_layout(rect=[0.05, 0.08, 0.95, 0.95])
# add_footer(fig, 6, total_p)
# pdf.savefig(fig, dpi=300); plt.close()
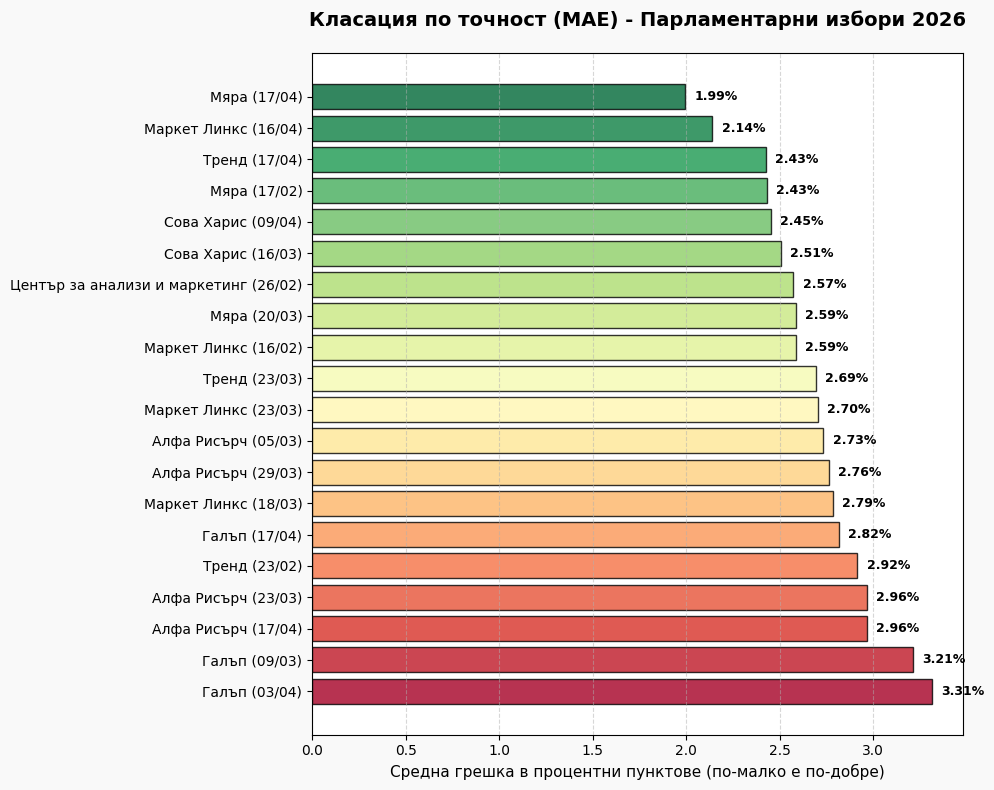
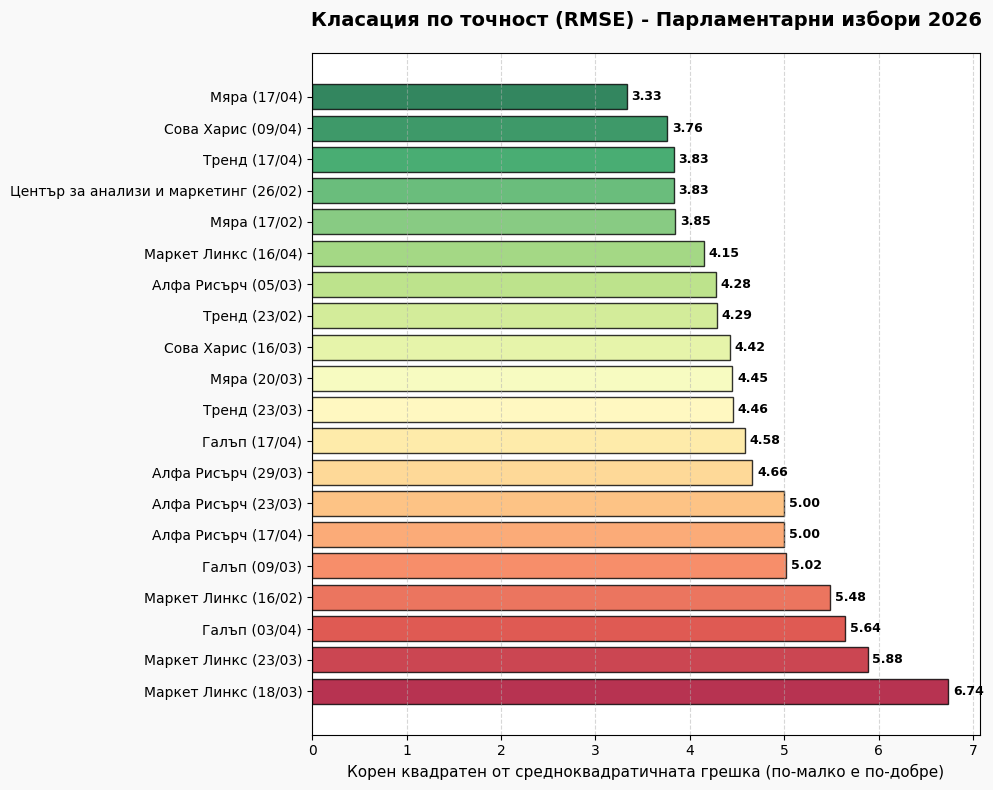
# # --- СТРАНИЦА 2: RMSE СРЕЩУ MAE ---
# metrics_summary = metrics_all_df.sort_values('RMSE')
# fig, ax = plt.subplots(figsize=PAGE_SIZE)
# y_indices = np.arange(len(metrics_summary))
# ax.barh(y_indices - 0.17, metrics_summary['MAE'], 0.35, label='MAE', color='#3498db', alpha=0.8, edgecolor='black')
# ax.barh(y_indices + 0.17, metrics_summary['RMSE'], 0.35, label='RMSE', color='#e74c3c', alpha=0.8, edgecolor='black')
# ax.set_yticks(y_indices); ax.set_yticklabels(metrics_summary.index); ax.invert_yaxis()
# ax.set_title('Сравнение на точността по агенции\n', fontsize=16, fontweight='bold')
# ax.text(0.5, 1.02, 'Агрегирани стойности на MAE и RMSE спрямо официалния резултат', transform=ax.transAxes, ha='center', fontsize=11, color='#555')
# ax.legend(); ax.grid(axis='x', linestyle='--', alpha=0.3)
# plt.tight_layout(rect=[0.05, 0.08, 0.95, 0.92])
# add_footer(fig, 2, total_p)
# pdf.savefig(fig, dpi=300); plt.close()
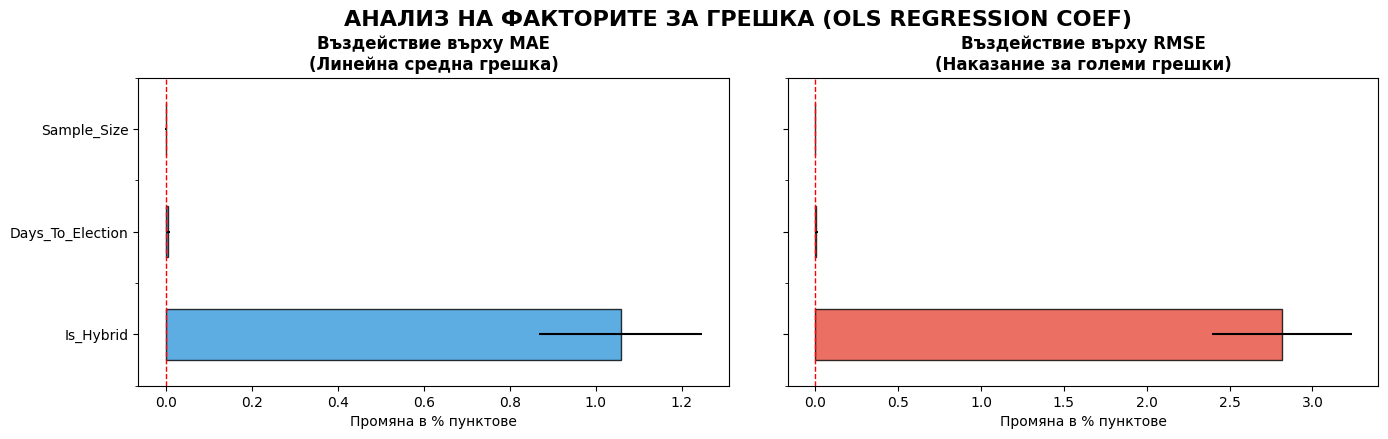
# # --- СТРАНИЦА 3: OLS КОЕФИЦИЕНТИ (С ТИТЛИ И ПОДЗАГЛАВИЯ) ---
# fig, (ax1, ax2) = plt.subplots(1, 2, figsize=PAGE_SIZE, sharey=True)
# model_mae.params[1:].plot(kind='barh', xerr=model_mae.bse[1:], color='#3498db', ax=ax1, alpha=0.8, edgecolor='black')
# ax1.axvline(0, color='red', linestyle='--', linewidth=1)
# ax1.set_title('Въздействие върху MAE\n', fontsize=13, fontweight='bold')
# ax1.text(0.5, 1.02, 'Как факторите променят линейната грешка (%)', transform=ax1.transAxes, ha='center', fontsize=9, color='#555')
# model_rmse.params[1:].plot(kind='barh', xerr=model_rmse.bse[1:], color='#e74c3c', ax=ax2, alpha=0.8, edgecolor='black')
# ax2.axvline(0, color='red', linestyle='--', linewidth=1)
# ax2.set_title('Въздействие върху RMSE\n', fontsize=13, fontweight='bold')
# ax2.text(0.5, 1.02, 'Тежест на факторите при големи отклонения', transform=ax2.transAxes, ha='center', fontsize=9, color='#555')
# plt.suptitle('СТАТИСТИЧЕСКА ЗНАЧИМОСТ НА ФАКТОРИТЕ (OLS)', fontsize=16, fontweight='bold', y=0.96)
# # Свиване на графиките надолу чрез rect [left, bottom, right, top]
# plt.tight_layout(rect=[0.05, 0.12, 0.95, 0.88])
# add_footer(fig, 3, total_p)
# pdf.savefig(fig, dpi=300); plt.close()
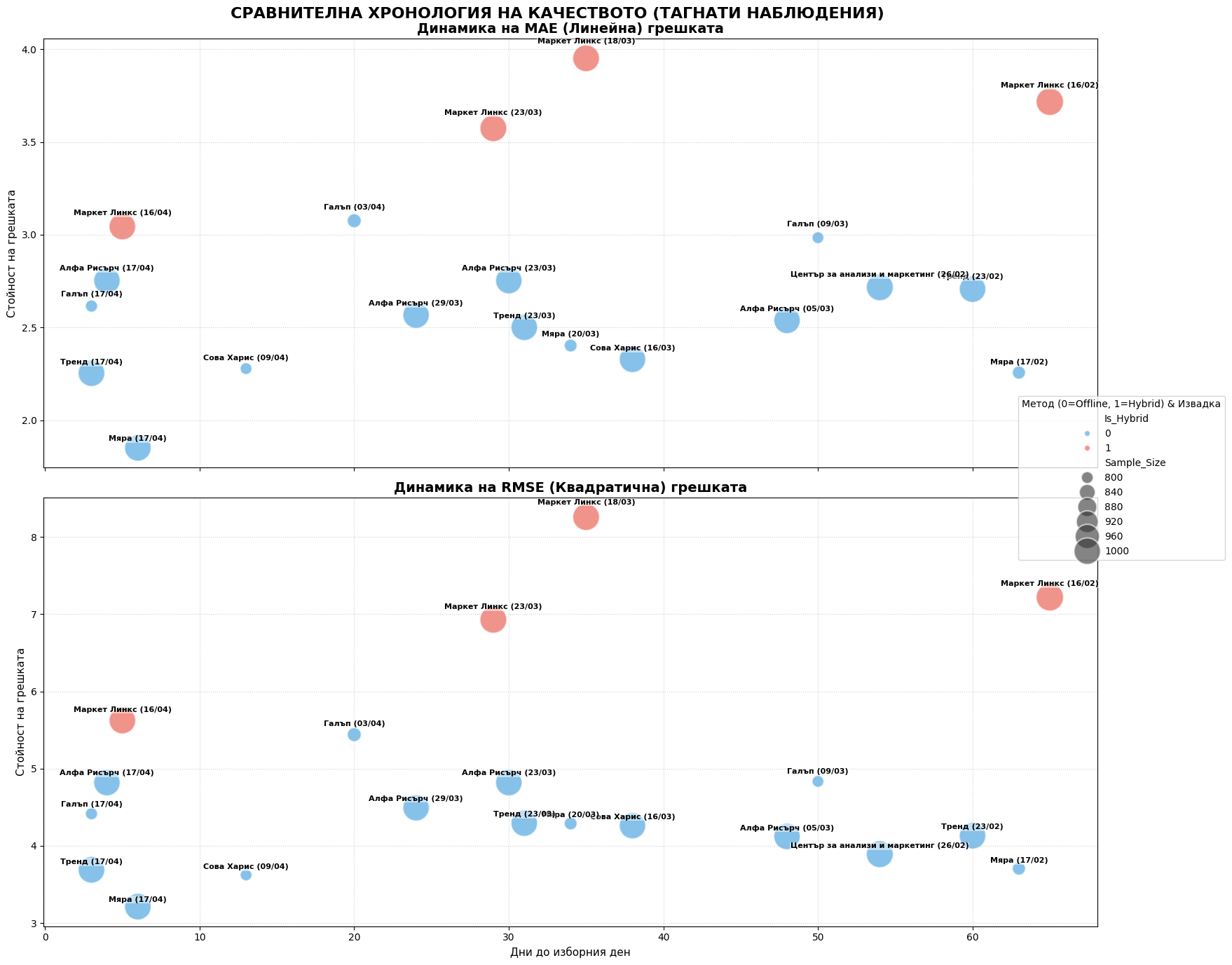
# # --- СТРАНИЦА 4: SIDE-BY-SIDE ДИНАМИКА (С ТИТЛИ И ПОДЗАГЛАВИЯ) ---
# fig, (ax3, ax4) = plt.subplots(1, 2, figsize=PAGE_SIZE)
# titles = ['MAE Dynamics', 'RMSE Dynamics']
# subtitles = ['Линейно отклонение във времето', 'Квадратично наказание за големи грешки']
# for ax, metric, color, title, sub in zip([ax3, ax4], ['MAE', 'RMSE'], ['#3498db', '#e74c3c'], titles, subtitles):
# sns.scatterplot(data=reg_df, x='Days_To_Election', y=metric, hue='Is_Hybrid', size='Sample_Size',
# sizes=(100, 700), palette={0: '#3498db', 1: '#e74c3c'}, alpha=0.6, edgecolor='black', ax=ax)
# for _, row in reg_df.iterrows():
# ax.text(row['Days_To_Election'], row[metric], s=row['Label'], fontsize=7, rotation=45, ha='left', va='bottom')
# ax.invert_xaxis(); ax.grid(True, linestyle=':', alpha=0.6)
# ax.set_title(f'{title}\n', fontsize=13, fontweight='bold')
# ax.text(0.5, 1.02, sub, transform=ax.transAxes, ha='center', fontsize=9, color='#555')
# ax.get_legend().remove()
# handles, labels = ax4.get_legend_handles_labels()
# fig.legend(handles, labels, title='Метод (0=F2F, 1=Hybrid)', loc='center right', bbox_to_anchor=(0.98, 0.5))
# plt.suptitle('ХРОНОЛОГИЧНО РАЗПРЕДЕЛЕНИЕ НА ТОЧНОСТТА', fontsize=16, fontweight='bold', y=0.96)
# # Свиване на графиките надолу
# plt.tight_layout(rect=[0.05, 0.1, 0.88, 0.88])
# add_footer(fig, 4, total_p)
# pdf.savefig(fig, dpi=300); plt.close()
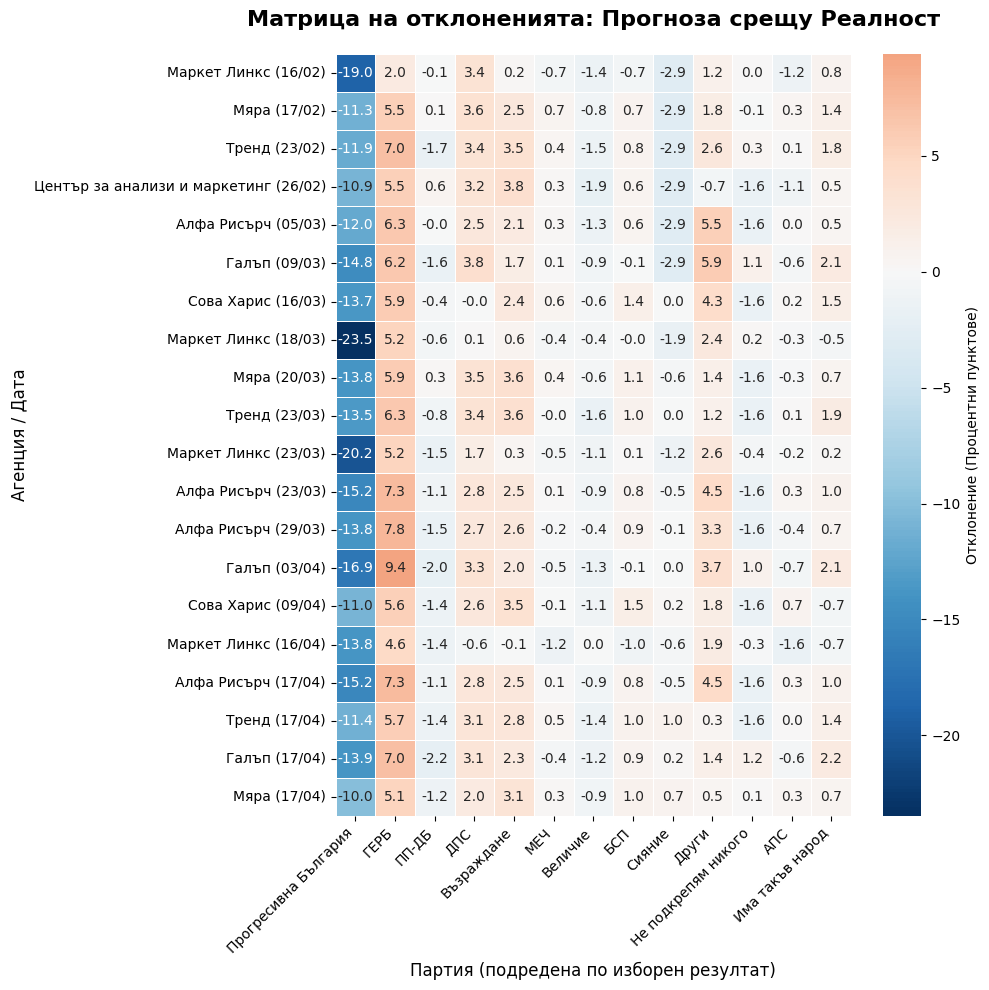
# # --- СТРАНИЦА 5: МАТРИЦА НА ОТКЛОНЕНИЯТА ---
# residuals = df[cols].sub(actual[cols], axis=1)
# fig = plt.figure(figsize=PAGE_SIZE)
# sns.heatmap(residuals[sorted_parties], annot=True, fmt='.1f', cmap='RdBu_r', center=0, annot_kws={"size": 8}, cbar_kws={'shrink': 0.8})
# plt.title('Матрица на отклоненията (Прогноза - Реалност)', fontsize=16, fontweight='bold')
# plt.xticks(rotation=45, ha='right', fontsize=9); plt.yticks(fontsize=8)
# plt.tight_layout(rect=[0.05, 0.08, 0.95, 0.95])
# add_footer(fig, 5, total_p)
# pdf.savefig(fig, dpi=300); plt.close()
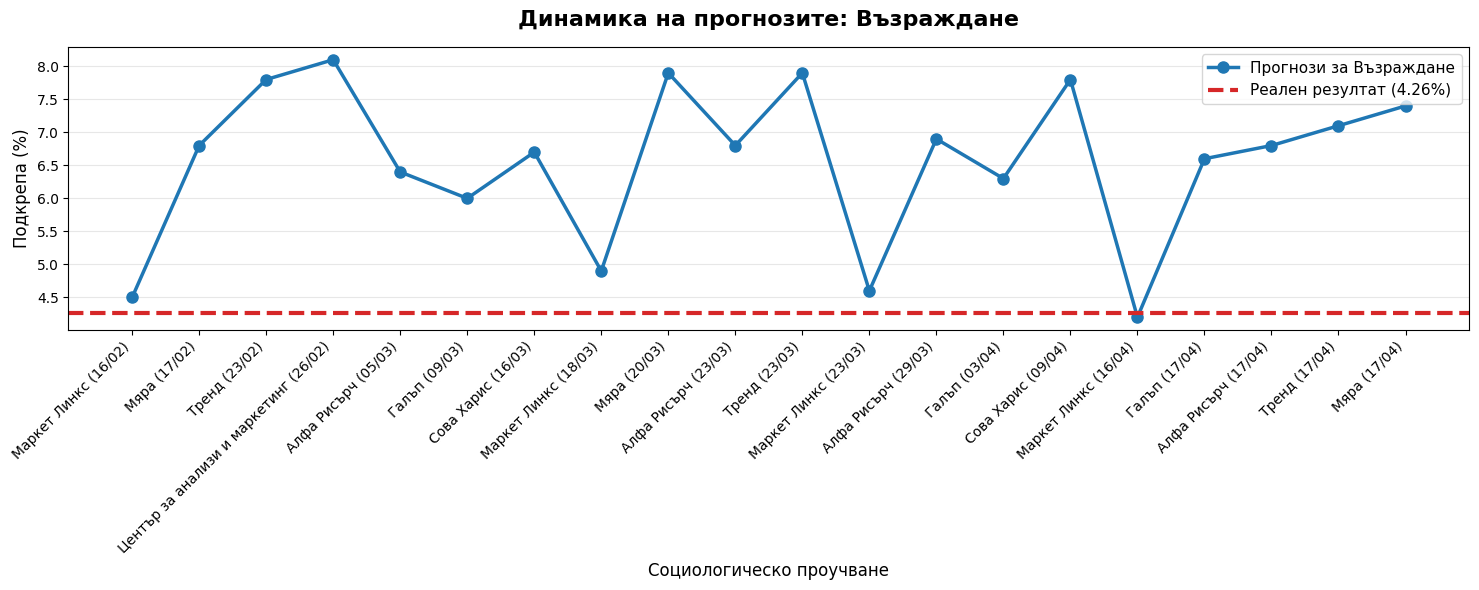
# # --- СТРАНИЦИ 7-N: ТРЕНДОВЕ ---
# curr_p = 7
# trend_df = df.sort_values('Date')
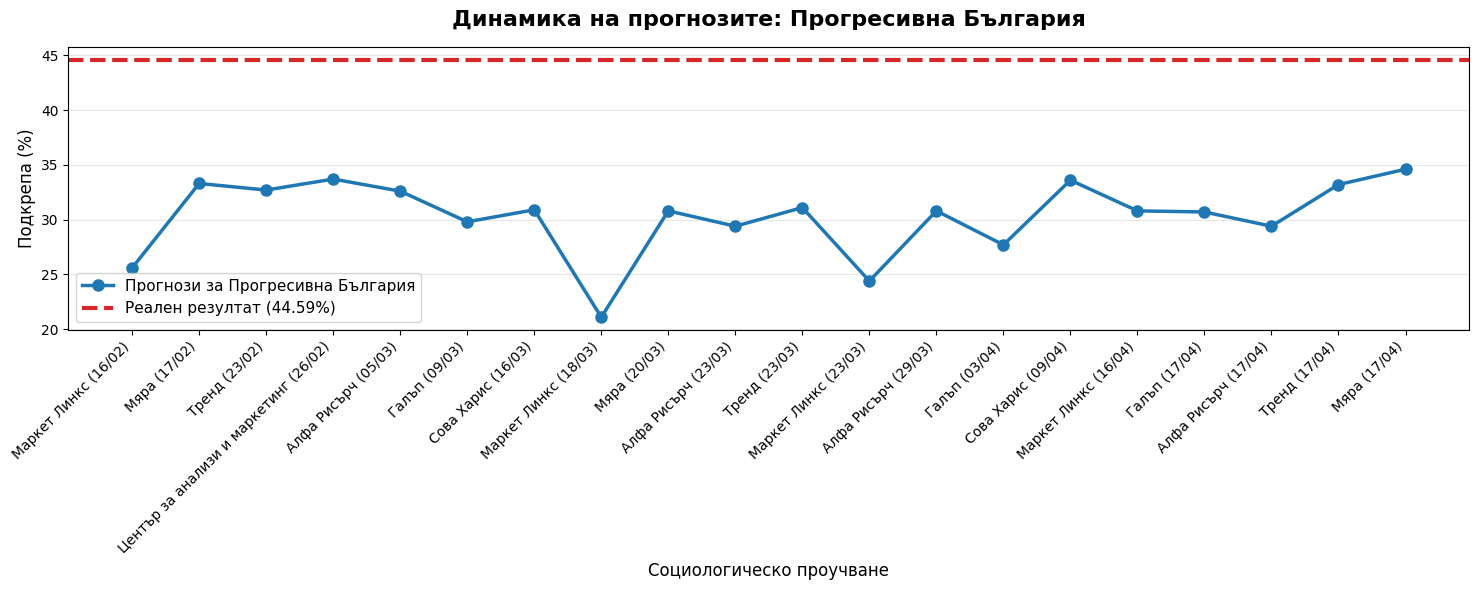
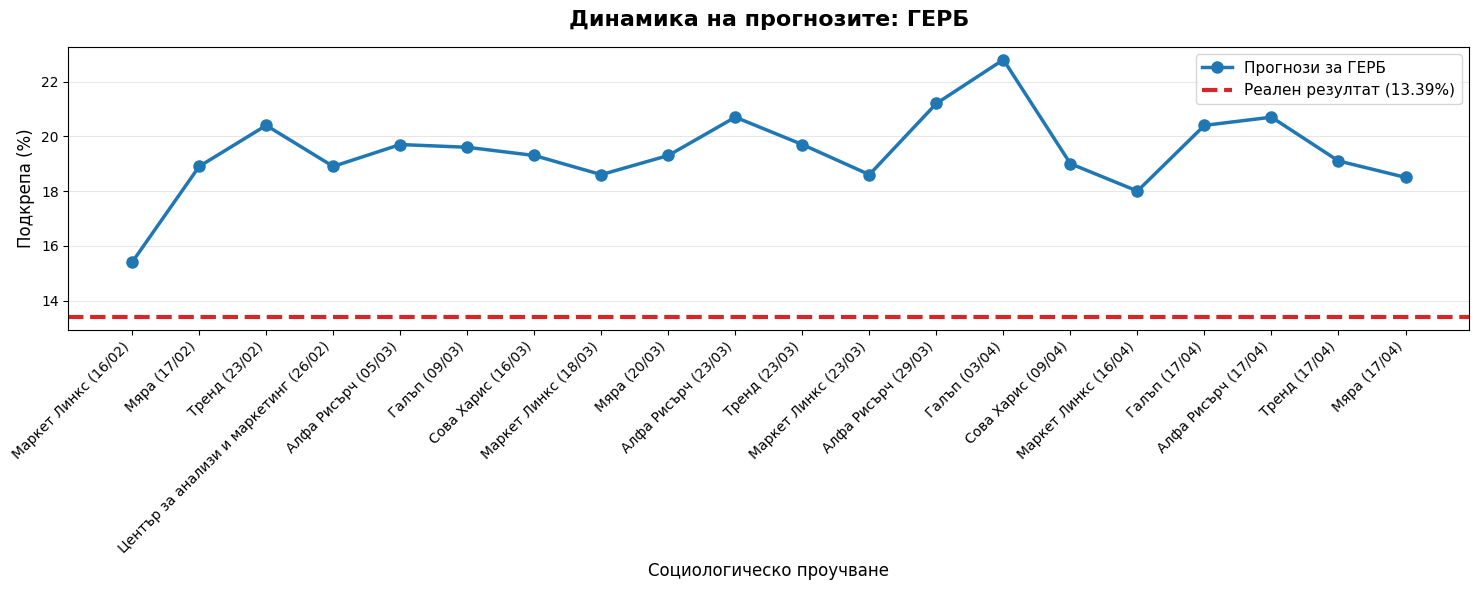
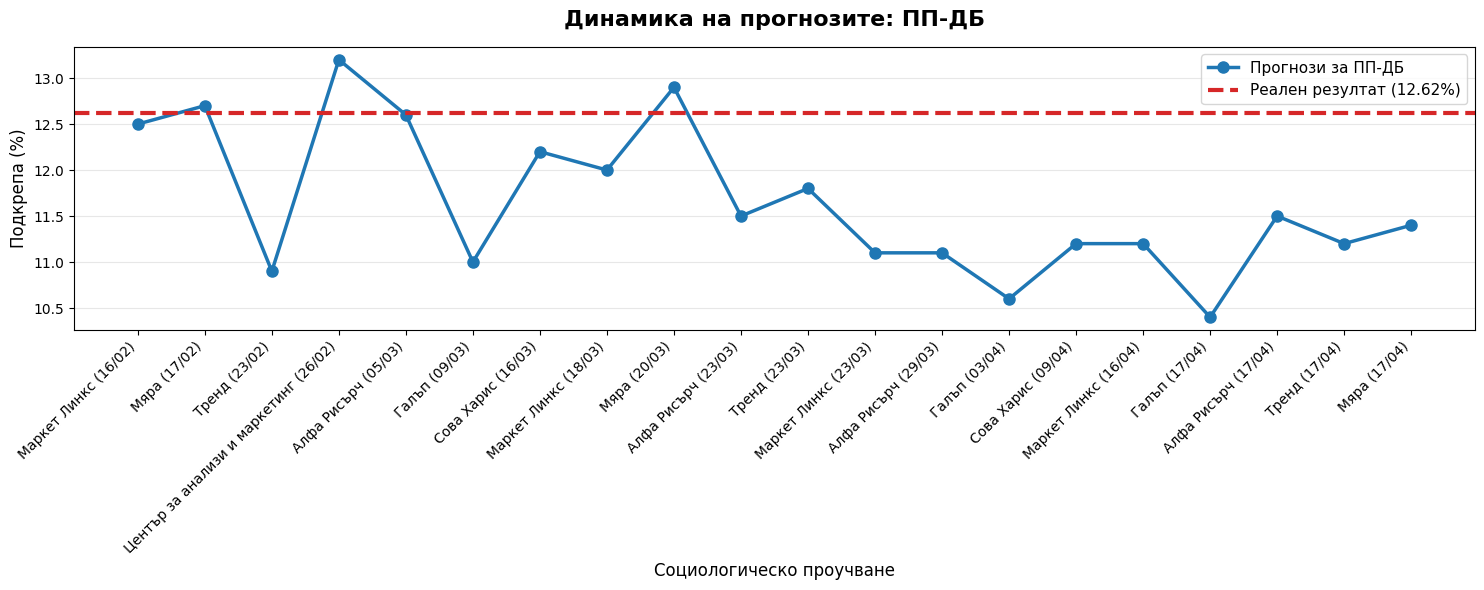
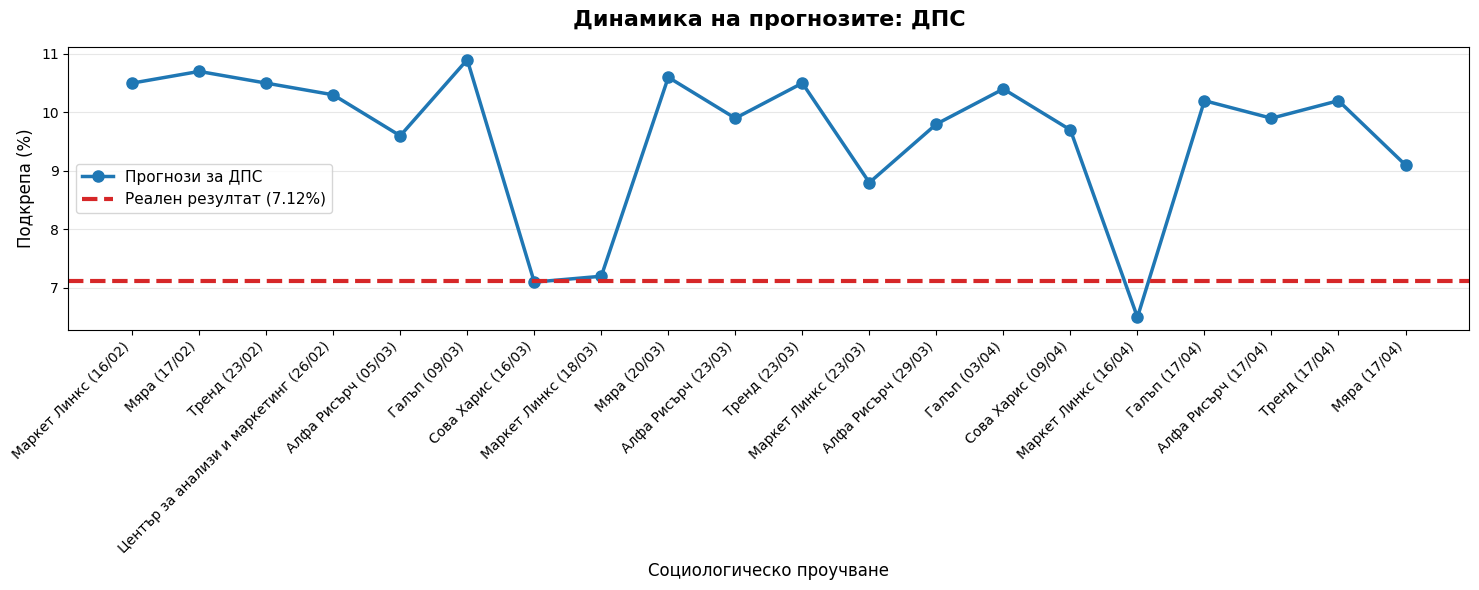
# for party in target_parties:
# if party in trend_df.columns:
# fig = plt.figure(figsize=PAGE_SIZE)
# plt.plot(trend_df.index, trend_df[party], marker='o', color='#1f77b4', linewidth=2)
# plt.axhline(y=actual[party], color='#d62728', linestyle='--', linewidth=3, label=f'Реалност ({actual[party]}%)')
# plt.title(f'Тренд на прогнозите: {party}', fontsize=16, fontweight='bold')
# plt.xticks(rotation=45, ha='right', fontsize=8); plt.legend(); plt.grid(alpha=0.3)
# plt.tight_layout(rect=[0.05, 0.08, 0.95, 0.95])
# add_footer(fig, curr_p, total_p)
# pdf.savefig(fig, dpi=300); plt.close()
# curr_p += 1
# # --- ФИНАЛНА СТРАНИЦА: ЗАКЛЮЧЕНИЯ ---
# fig = plt.figure(figsize=PAGE_SIZE)
# plt.axis('off')
# plt.text(0.05, 0.92, 'Заключение и изводи от анализа', fontsize=20, fontweight='bold', color='#003366')
# y_pos = 0.82
# conclusion_blocks = [
# ("• Системен пропуск:", "Всички агенции подцениха победителя (Прогресивна България) с над 10% средно отклонение.", True),
# ("", "Всички агенции надцениха установените играчи (ГЕРБ, ДПС, Възраждане) в различна степен.", True),
# ("• Методология:", "Необходима е ревизия на моделите за разпределение на гласовете на нерешилите избиратели.", False),
# ("", "Необходима е критична ревизия на източниците и структурирането на извадката.", True),
# ("• Информационна хигиена:", "Ефирът е пълен с демографски, психографски и поведенчески разпределения на вота, към които", False),
# ("", "трябва да се подходи със скептицизъм, имайки предвид мащаба на анализираните отклонения.", False),
# ("", "Анализи на по-малки кохорти (напр. от типа коя партия е донор на гласоподаватели)", False),
# ("", "носят риск да са значително по-неточни.", False),
# ("• Забележка:", "Нормализирането на толкова голям набор от изследвания изисква задълбочена работа.", False),
# ("", "Този анализ е по-скоро отправна точка за по-задълбочени бъдещи мета-анализи, целящи повишаване на прогнозната сила.", False),
# ("", "Най-належащата задача би била ръчното преглеждане и коригиране на входящите данни.", False),
# ]
# for header, detail, add_space in conclusion_blocks:
# if header: plt.text(0.05, y_pos, header, fontsize=13, fontweight='bold', color='#003366'); y_pos -= 0.05
# plt.text(0.07, y_pos, detail, fontsize=12, color='#333333'); y_pos -= 0.05
# if add_space: y_pos -= 0.02
# rect = plt.Rectangle((0.03, 0.15), 0.94, 0.80, linewidth=1, edgecolor='#cccccc', facecolor='#f9f9f9', alpha=0.3, zorder=-1)
# fig.patches.append(rect)
# add_footer(fig, total_p, total_p)
# pdf.savefig(fig, dpi=300, bbox_inches='tight'); plt.close()
# print(f"✅ Докладът е генериран успешно: {pdf_filename}")
# files.download(pdf_filename)