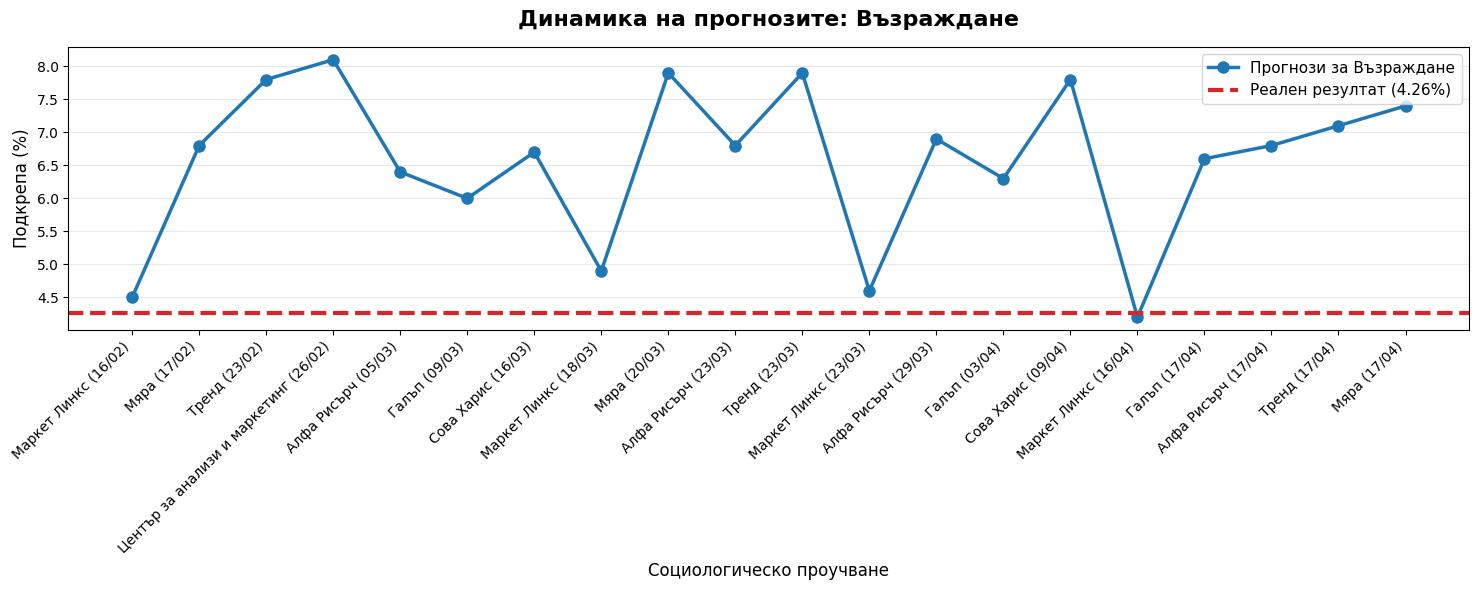
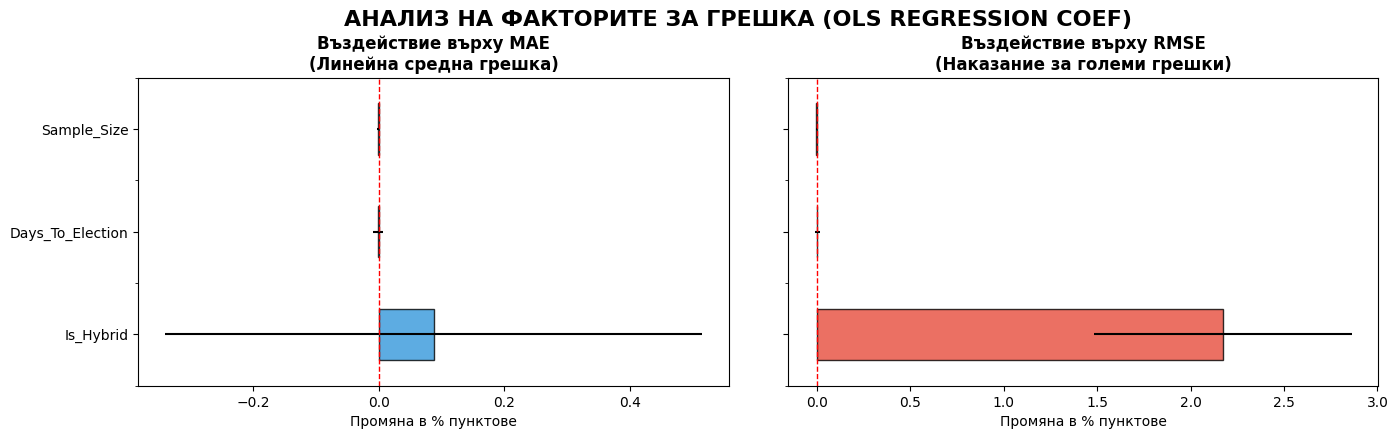
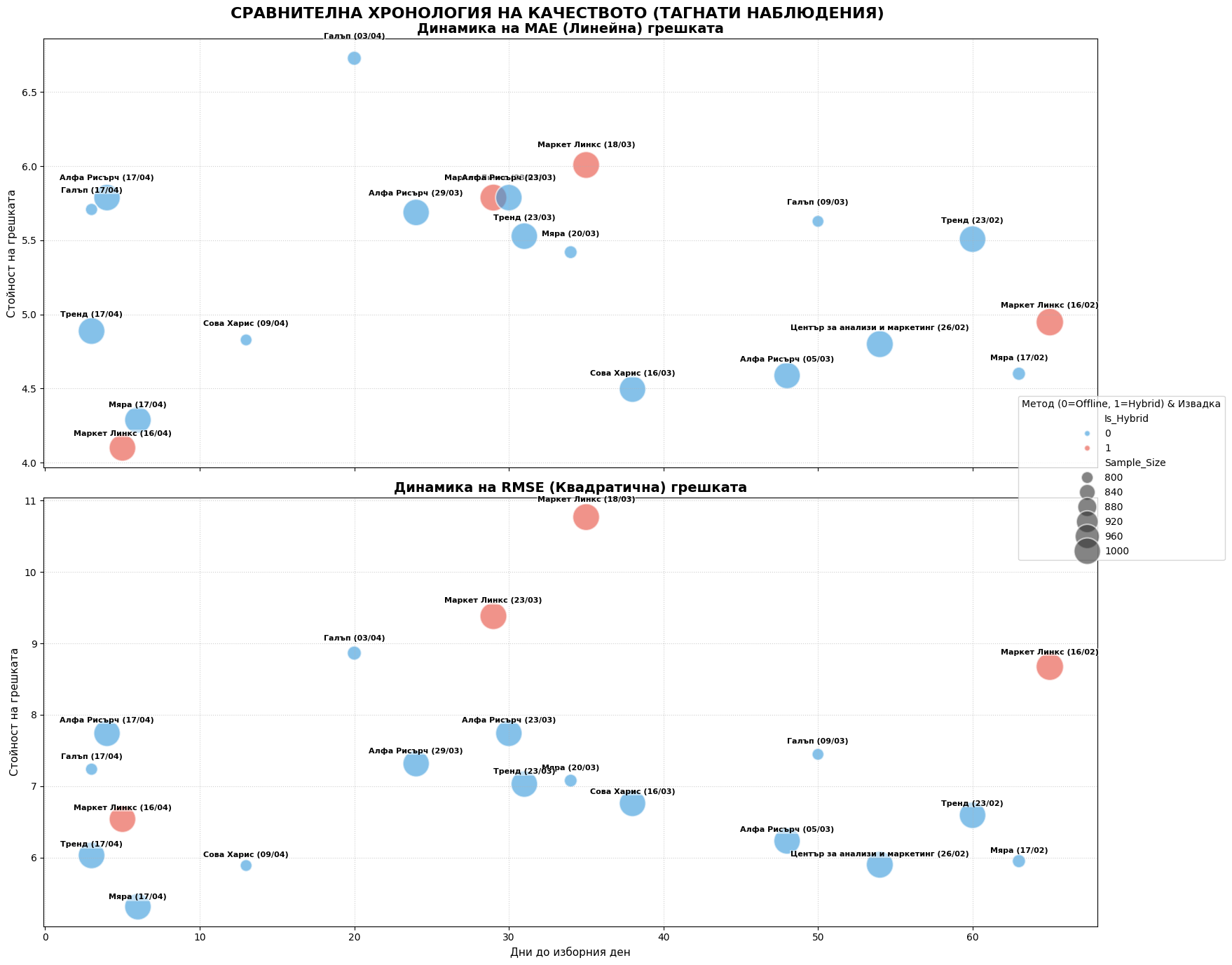
import statsmodels.api as sm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# --- 1. ПРЕЦИЗНО ИЗЧИСЛЯВАНЕ НА МЕТРИКИТЕ ---
# party_cols = [c for c in df.columns if c in actual.index]
party_cols = ['Прогресивна България',
'ГЕРБ',
'ПП-ДБ',
'ДПС',
'Възраждане',
#'БСП',
#'MEЧ',
#'Има такъв народ',
#'Величие',
#'Не подкрепям никого',
#'Сияние',
#'АПС'
]
print(df.columns)
print(party_cols)
def calculate_metrics(row):
diffs = row[party_cols] - actual[party_cols]
return pd.Series({
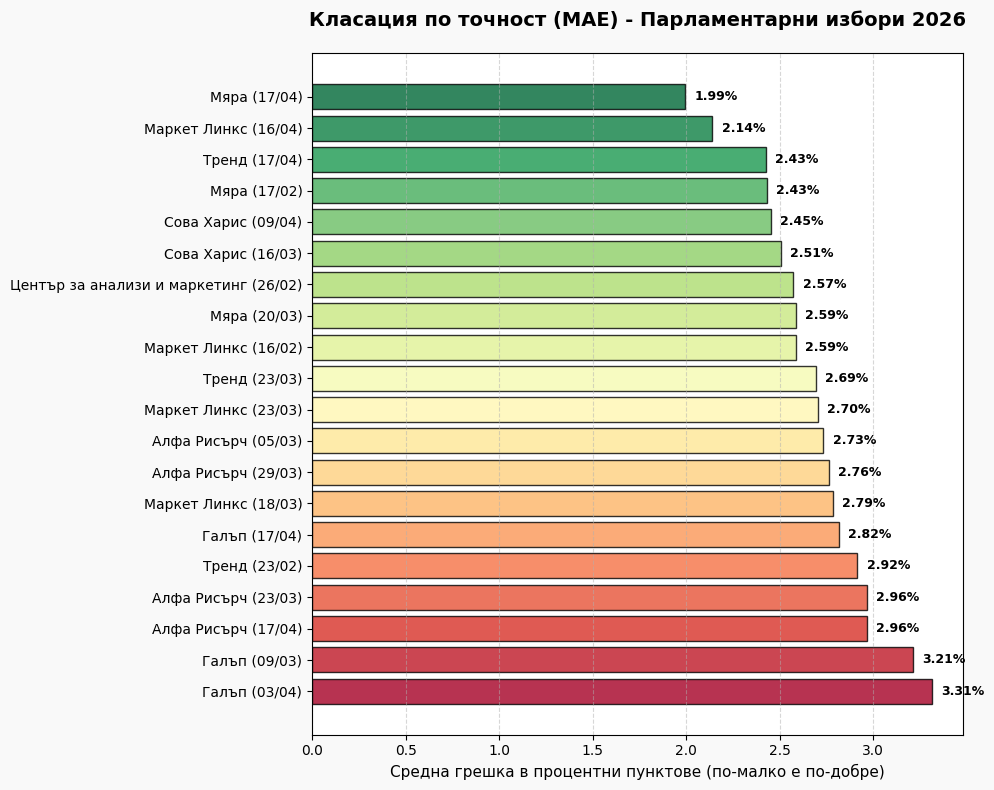
'MAE': np.abs(diffs).mean(),
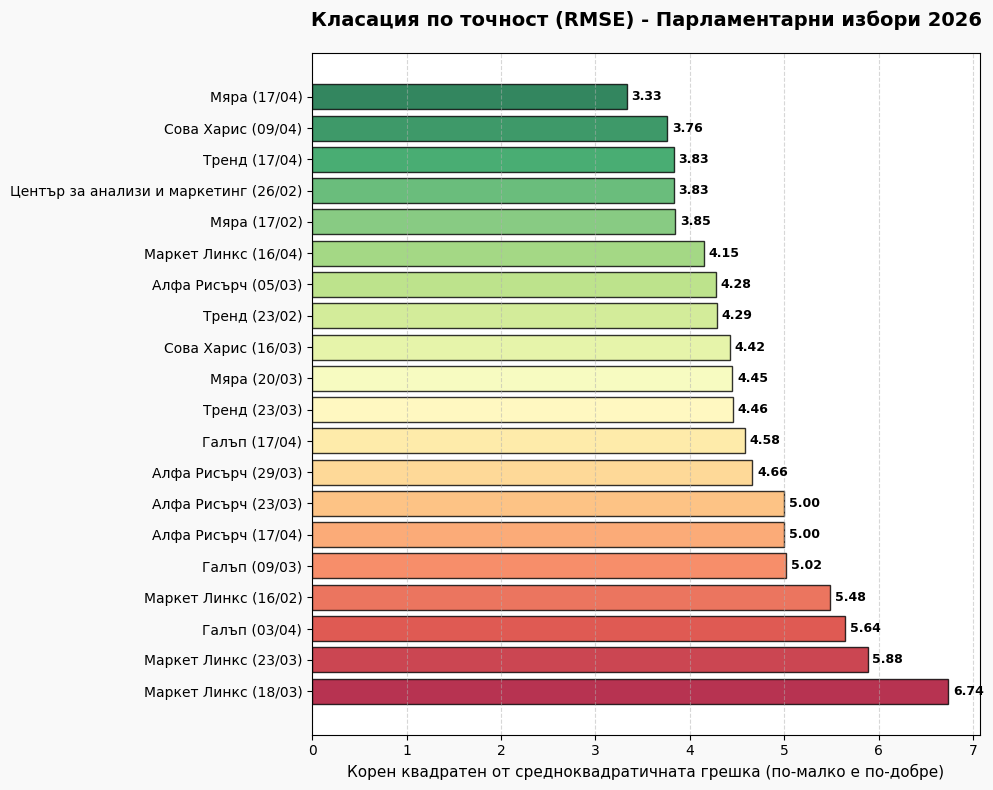
'RMSE': np.sqrt((diffs**2).mean())
})
metrics_df = df.apply(calculate_metrics, axis=1)
# --- 2. ПОДГОТОВКА НА ДАННИТЕ ЗА РЕГРЕСИЯ ---
election_date = pd.to_datetime('2026-04-19')
ols_data = []
for idx, row in df.iterrows():
enc = row['metadata'].get('encoded', {})
if not enc: continue
ols_data.append({
'Label': idx,
'MAE': metrics_df.loc[idx, 'MAE'],
'RMSE': metrics_df.loc[idx, 'RMSE'],
'Is_Hybrid': 1 if enc.get('methodology') == 'hybrid' else 0,
'Days_To_Election': (election_date - pd.to_datetime(enc.get('date'))).days,
'Sample_Size': enc.get('sample_size', 0)
})
reg_df = pd.DataFrame(ols_data).set_index('Label').dropna()
# --- 3. ИЗПЪЛНЕНИЕ НА РЕГРЕСИИТЕ ---
X = sm.add_constant(reg_df[['Is_Hybrid', 'Days_To_Election', 'Sample_Size']])
model_mae = sm.OLS(reg_df['MAE'], X).fit()
model_rmse = sm.OLS(reg_df['RMSE'], X).fit()
# --- 4. ВИЗУАЛИЗАЦИЯ 1: ВЛИЯНИЕ НА ФАКТОРИТЕ (КОЕФИЦИЕНТИ) ---
fig1, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 4), sharey=True)
plt.subplots_adjust(wspace=0.1)
# MAE Coefs
model_mae.params[1:].plot(kind='barh', xerr=model_mae.bse[1:], color='#3498db', ax=ax1, alpha=0.8, edgecolor='black')
ax1.axvline(0, color='red', linestyle='--', linewidth=1)
ax1.set_title('Въздействие върху MAE\n(Линейна средна грешка)', fontweight='bold')
ax1.set_xlabel('Промяна в % пунктове')
# RMSE Coefs
model_rmse.params[1:].plot(kind='barh', xerr=model_rmse.bse[1:], color='#e74c3c', ax=ax2, alpha=0.8, edgecolor='black')
ax2.axvline(0, color='red', linestyle='--', linewidth=1)
ax2.set_title('Въздействие върху RMSE\n(Наказание за големи грешки)', fontweight='bold')
ax2.set_xlabel('Промяна в % пунктове')
plt.suptitle('АНАЛИЗ НА ФАКТОРИТЕ ЗА ГРЕШКА (OLS REGRESSION COEF)', fontsize=16, fontweight='bold', y=1.05)
plt.show()
# --- 5. ВИЗУАЛИЗАЦИЯ 2: SIDE-BY-SIDE ТАГНАТА ДИНАМИКА (MAE vs RMSE) ---
fig2, (ax3, ax4) = plt.subplots(2, 1, figsize=(16, 14), sharex=True)
palette = ['#3498db', '#e74c3c']
for ax, metric, color, title in zip([ax3, ax4], ['MAE', 'RMSE'], palette, ['MAE (Линейна)', 'RMSE (Квадратична)']):
# Scatter plot
sns.scatterplot(
data=reg_df, x='Days_To_Election', y=metric,
hue='Is_Hybrid', size='Sample_Size', sizes=(150, 800),
palette=palette, alpha=0.6, edgecolor='white', linewidth=1.5, ax=ax
)
# Тагване на всяка точка
for label, row in reg_df.iterrows():
ax.text(
x=row['Days_To_Election'],
y=row[metric] + (row[metric] * 0.02), # динамично отместване нагоре
s=label, fontsize=8, fontweight='semibold', ha='center',
bbox=dict(facecolor='white', alpha=0.5, edgecolor='none', pad=0.5)
)
ax.invert_xaxis()
ax.set_title(f'Динамика на {title} грешката', fontsize=14, fontweight='bold')
ax.set_xlabel('Дни до изборния ден', fontsize=11)
ax.set_ylabel('Стойност на грешката', fontsize=11)
ax.grid(True, linestyle=':', alpha=0.6)
ax.get_legend().remove() # премахваме индивидуалните легенди за по-чист вид
# Единна легенда за целия плот
handles, labels = ax4.get_legend_handles_labels()
fig2.legend(handles, labels, title='Метод (0=Offline, 1=Hybrid) & Извадка', loc='center right', bbox_to_anchor=(1.1, 0.5))
plt.suptitle('СРАВНИТЕЛНА ХРОНОЛОГИЯ НА КАЧЕСТВОТО (ТАГНАТИ НАБЛЮДЕНИЯ)', fontsize=16, fontweight='bold', y=0.98)
plt.tight_layout()
plt.show()
# --- 6. СТРУКТУРИРАН ТЕКСТОВ АУТПУТ ---
print("\n" + "="*60)
print(" СРАВНИТЕЛЕН АНАЛИЗ НА КОЕФИЦИЕНТИТЕ (MAE vs RMSE)")
print("="*60)
summary_table = pd.DataFrame({
'Metric': ['Is_Hybrid', 'Days_To_Election', 'Sample_Size'],
'MAE Coef': model_mae.params[1:].values,
'MAE P-value': model_mae.pvalues[1:].values,
'RMSE Coef': model_rmse.params[1:].values,
'RMSE P-value': model_rmse.pvalues[1:].values
}).round(4)
print(summary_table.to_string(index=False))
print("="*60)